#include <cmath>
#include <cstddef>
#include <memory>
#include <gdk-pixbuf/gdk-pixbuf.h>
#include <printf.hpp>
#include <hpc/aux/hsvcolor.hpp>
#include <hpc/aux/rgbcolor.hpp>
#include <hpc/cuda/check.hpp>
#include <hpc/cuda/copy.hpp>
#include <hpc/cuda/gematrix.hpp>
#include <hpc/cuda/properties.hpp>
#include <hpc/matvec/gematrix.hpp>
#include <hpc/matvec/matrix2pixbuf.hpp>
using T = double;
using namespace hpc;
template<
template<typename> class Matrix,
typename T,
Require< DeviceGe<Matrix<T>>, DeviceView<Matrix<T>> > = true
>
__global__ void init_matrix(Matrix<T> A) {
std::size_t i = threadIdx.x + blockIdx.x * blockDim.x;
std::size_t j = threadIdx.y + blockIdx.y * blockDim.y;
const auto PI = std::acos(-T(1.0));
const auto E = std::exp(T(1.0));
const auto E_POWER_MINUS_PI = std::pow(E, -PI);
std::size_t N = A.numRows();
T value;
if (j == N-1) {
value = std::sin(M_PI * (T(i)/N)) * E_POWER_MINUS_PI;
} else if (j == 0) {
value = std::sin(M_PI * (T(i)/N));
} else {
value = 0;
}
A(i, j) = value;
}
template<
template<typename> class Matrix,
typename T,
Require< DeviceGe<Matrix<T>>, DeviceView<Matrix<T>> > = true
>
__global__ void init_matrix_border(Matrix<T> A) {
std::size_t index = threadIdx.x + blockIdx.x * blockDim.x;
const auto PI = std::acos(-T(1.0));
const auto E = std::exp(T(1.0));
const auto E_POWER_MINUS_PI = std::pow(E, -PI);
std::size_t N = A.numRows();
A(index, N-1) = std::sin(M_PI * (T(index)/N)) *
E_POWER_MINUS_PI;
A(index, 0) = std::sin(M_PI * (T(index)/N));
if (index > 0 && index < N-1) {
A(0, index) = 0; A(N-1, index) = 0;
}
}
template<
template<typename> class MatrixA,
template<typename> class MatrixB,
typename T,
Require<
DeviceGe<MatrixA<T>>, DeviceView<MatrixA<T>>,
DeviceGe<MatrixB<T>>, DeviceView<MatrixB<T>>
> = true
>
__global__ void jacobi_iteration(const MatrixA<T> A, MatrixB<T> B) {
std::size_t i = threadIdx.y + blockIdx.y * blockDim.y;
std::size_t j = threadIdx.x + blockIdx.x * blockDim.x;
T value;
if (i == 0 || j == 0 || i == A.numRows()-1 || j == A.numCols()-1) {
value = A(i, j);
} else {
value = 0.25 *
(A(i-1, j) + A(i, j-1) + A(i, j+1) + A(i+1, j));
}
B(i, j) = value;
}
template<typename T>
constexpr T int_sqrt(T n) {
T result = 1;
while (result * result <= n) {
++result;
}
return result - 1;
}
int main() {
using namespace hpc::aux;
using namespace hpc::cuda;
using namespace hpc::matvec;
const std::size_t max_threads = get_max_threads_per_block();
const std::size_t BLOCK_DIM = int_sqrt(max_threads);
const std::size_t GRID_DIM = 2;
const std::size_t N = BLOCK_DIM * GRID_DIM;
GeMatrix<T> A(N, N, Order::ColMajor);
DeviceGeMatrix<T> devA(A.numRows(), A.numCols(), Order::ColMajor);
DeviceGeMatrix<T> devB(A.numRows(), A.numCols(), Order::ColMajor);
dim3 block_dim(BLOCK_DIM, BLOCK_DIM);
dim3 grid_dim(GRID_DIM, GRID_DIM);
init_matrix<<<grid_dim, block_dim>>>(devA.view());
init_matrix_border<<<grid_dim, BLOCK_DIM>>>(devB.view());
auto A_ = devA.view(); auto B_ = devB.view();
std::size_t iterations = 0;
while (iterations < 1941) {
jacobi_iteration<<<grid_dim, block_dim>>>(A_, B_); ++iterations;
jacobi_iteration<<<grid_dim, block_dim>>>(B_, A_); ++iterations;
}
copy(B_, A);
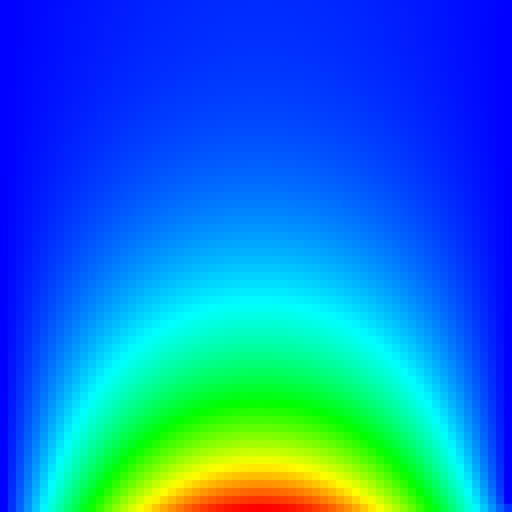
auto pixbuf = create_pixbuf(A, [](T val) -> HSVColor<double> {
return HSVColor<T>((1-val) * 240, 1, 1);
}, 8);
gdk_pixbuf_save(pixbuf, "jacobi.jpg", "jpeg", nullptr,
"quality", "100", nullptr);
}