Zu den im ersten Abschnitt festgelegten Eigenschaften unserer Namensräume gehört auch die Forderung, daß beliebige Objekte in den Graphen eingebunden werden können sollen. Diese Möglichkeit wird von dem Modul NamedObjects eingeführt.
Diese Abstraktion erfüllt eine Aufgabe, die in manchen Programmiersprachen im Wege von Mehrfachvererbung (multiple inheritance) lösbar wäre, nämlich Objekte mit Merkmalen aus verschiedenen unabhängigen Abstraktionen zu versehen. In Oberon stehen hierfür andere Techniken zur Verfügung. Handelte es sich bei den gewünschten Merkmalen um eine Art Dienst, der je nach vorliegendem Datentyp stark unterschiedlich zu implementieren wäre, wäre die Verwendung der Services-Schnittstelle angebracht. In diesem konkreten Fall ist allerdings kein so "schweres Geschütz" erforderlich, denn aus der Sicht des Namensraumes ist der Typ eines Objekts, das lediglich als Referenz betrachtet, von dem aber keine Methode verwendet wird, praktisch unerheblich.
Das Mittel der Wahl ist hier die Delegation auf der Basis von Filterobjekten. Ein Filterobjekt ist ein Objekt, das Aufträge entweder selbst bearbeitet oder an ein angekoppeltes Objekt weiterleitet, je nachdem, ob es sie kennt oder nicht. Dadurch wirkt es insgesamt wie ein einziges Objekt mit einem erweiterten Sprachschatz.
Dieses Codefragment zeigt die Methoden dieser Abstraktion:
Create erzeugt einen neuen Knoten, der das angegebene Objekt repräsentiert und Aufträge an es weiterleitet. Voraussetzung ist, daß für das Objekt nicht bereits ein solcher Knoten existiert. Dieser Knoten wird als gewöhnlicher Knoten ohne die Fähigkeit, Unterknoten zu erzeugen, angelegt. Soll der Knoten ein Objekt ohne weitere statische Merkmale darstellen, kann auch NIL angegeben werden. Zusätzliche Auftragsbearbeiter wären dann direkt an den Knoten anzuhängen.
Die Kopplung zwischen einem Filterobjekt und dem Objekt, an das delegiert wird, ist als besonders eng zu betrachten. Damit das repräsentierte Objekt nicht damit rechnen muß, seine Namen -- etwa durch einen Aufruf von Names.Destroy von dritter Seite -- unerwartet einzubüßen, wird dieser Zugriff auf den Knoten durch eine spezielle Autorisierung eingeschränkt. Das Filterobjekt kann jedoch jederzeit mit NamedObjects.Destroy wieder terminiert werden, vorausgesetzt, diese Methode wird im eigenen Prozeß aufgerufen. Letzteres wird durch die Verwendung von VolatileShards sichergestellt.
Das Vorschalten eines Filterobjekts bewirkt zwangsläufig, daß die Bearbeitung von Aufträgen um mindestens eine Stufe indirekter wird. Anwendungen, die NamedObjects bewußt einsetzen, können sich dieses zusätzlichen Aufwands wieder entledigen, indem sie das hinter dem Filter liegende Objekt bei Bedarf hervorholen. Dazu dienen die Methoden Get und GuardedGet, die sich lediglich darin unterscheiden, ob eine Typenzusicherung stattfindet oder nicht. GuardedGet prüft, ob das Objekt den erwarteten Typ besitzt, bevor es eine Zuweisung vornimmt, und vermeidet so einen Laufzeitfehler und Programmabbruch, falls dies tatsächlich nicht der Fall sein sollte.
![]()
Namensräume in der Form, wie sie die Abstraktion Names definiert, lassen insofern etwas Komfort vermissen, als konkrete Namen stets über mehrere Zwischenschritte aufgebaut werden müssen und daher z.B. nicht als einfache Konstanten angegeben werden können.
Dieses "Manko" versucht das Modul Paths auszugleichen, indem es einige Hilfsfunktionen zur Umwandlung von einfachen Zeichenketten in Pfade und Namen bereitstellt. Konkret definiert es für jede Names-Methode mit einem Parameter vom Typ Names.Name zwei äquivalente Varianten mit einem entweder absoluten oder relativen Pfad in Form einer Zeichenkette. Dieses Codefragment zeigt deren Definitionen.
Da einer Zeichenkette keine Ereignisse zugeordnet werden können, übernimmt jeweils ein errors-Argument die Rolle des Objekts, auf das sich eventuell auftretende Fehler beziehen. Innerhalb der durch ein Null-Byte begrenzten Zeichenkette gelten Schrägstriche als Trennzeichen zwischen Pfadkomponenten. Ein Pfad wird in der Weise aufgelöst, daß von Names.root bzw. dem angegebenen Knoten ausgehend für jede Komponente eine Kante gleichlautenden Namens durchlaufen wird, bis noch genau eine Komponente übrig ist. Der erreichte Knoten und die verbleibende Komponente bilden dann das Objekt und das Namensargument, mit dem die entsprechende Methode von Names aufgerufen wird. Für alle Autorisierungen wird das gleiche auth-Argument herangezogen. Sollte einer Kante aus irgendwelchen Gründen nicht gefolgt werden können, bricht der Vorgang vorzeitig ab.
In seiner jetzigen Fassung erspart das Modul Paths in vielen Fällen, wo Namen als gewöhnliche Zeichenketten vorliegen, eine gewisse Menge an Programmieraufwand. Allerdings wären noch Verbesserungen vorstellbar. So könnte z.B. die noch sehr simple, nicht allgemeingültige Art der Abbildung gewöhnlicher Zeichenketten auf Pfade surjektiv gemacht werden, indem für die Zeichen mit Sonderbedeutung eine Ersatzdarstellung eingeführt würde. Im Sinne größerer Flexibilität sollte Paths diese Abbildung nicht selbst festlegen, sondern eine Schnittstelle dafür anbieten. Eine gute Standardimplementierung könnte sich, um einer denkbaren späteren Integration in heterogene Systeme Vorschub zu leisten, an einem weitverbreiteten Konzept wie den im World Wide Web gebräuchlichen uniform resource identifiers [Berners-Lee94] orientieren, deren Format auch darauf abgestimmt ist, Zeichen, die in anderen Kontexten Probleme bereiten könnten, möglichst zu vermeiden. Damit würde das an Oberon-Objekte gebundene Namenssystem eine komfortable und unproblematische Transportmöglichkeit für ungebundene Pfade hinzugewinnen.
![]()
Bei verschiedenen Gelegenheiten entsteht ein Bedarf an unverwechselbaren, jedoch für sich allein genommen keine besondere Information tragenden Namen. Individualität hilft, jede Art von Konflikten zu vermeiden, die aus Verwechslungen resultieren würden. Indessen ist es von praktischer Relevanz, daß ein Unterscheidungsmerkmal nicht übermäßig redundant ausfällt -- ein Kraftfahrzeugkennzeichen soll beispielsweise auf eine bestimmte Fläche passen und dennoch aus einigem Abstand noch ablesbar sein. Ein weiterer Aspekt, der von Interesse sein kann, ist die Streuung innerhalb des gegebenen Wertebereichs. Im Gegensatz zu einer fortlaufenden Nummer kann ein scheinbar "zufällig" vergebener Name dazu benutzt werden, von einer de facto bestehenden zeitlichen Reihenfolge zu abstrahieren.
Das kleine Modul UniqueNames, dessen komplette Definition in diesem Codebeispiel dargestellt ist, realisiert Namen mit diesen drei Eigenschaften. Die Eindeutigkeit ergibt sich bereits aus der Abstraktion für Namensräume, denn Names gestattet das Einfügen weiterer Kanten, die von einem Knoten wegführen, nur mit noch nicht vorhandenen Namen. Da die Abstraktion auf parallele Benutzung eingerichtet ist, gibt es keine auch nur kurzzeitige Ungewißheit (race condition) bei der diesbezüglichen Entscheidung. UniqueNames "erfindet" notfalls einfach so oft einen anderen Namen, bis die Einfügeoperation klappt oder aus einem anderen Grund als dem der Duplizität abgelehnt wird.
Die erzeugten Namen sind Folgen von Klein- und Großbuchstaben. Um eine gute Streuung zu erzielen, werden Pseudozufallszahlen des Moduls Random eingesetzt; die Taktik bei Übereinstimmungen setzt sich aus dem Anfordern weiterer Pseudozufallszahlen und systematischen Veränderungen zusammen, um nicht ganz vom "Wohlverhalten" des Zufallsgenerators abhängig zu sein (obwohl dieser in der Praxis noch keinen Anlaß zu Beanstandungen gab). Die aktuelle Implementierung arbeitet mit Namen fixer Länge, was sicherlich aus einem theoretischen Blickwinkel beanstandet werden könnte, aber praxisgerecht ist, solange die gewählten Konstanten den zu gewärtigenden Größenordnungen angemessen sind. (Einer Länge von sieben entsprechen z.B. über eine Billion Kombinationen. Anwendungen, die derart viele verschiedene Namen benötigen, wären wohl auch aus anderen Gründen gut beraten, sich dazu einer Struktur aus mehreren Knoten zu bedienen.)
![]()
Den Konventionen für die Unterstützung entfernter Objekte gemäß wird der Dienst, Objekte der Abstraktion Names exportierbar zu machen, in einem Modul RemoteNames realisiert.
In der historischen Entwicklung der Oberon-Bibliothek wurden Module, die solche Dienstleistungen implementierten, im Laufe der Zeit immer einfacher und übersichtlicher, denn die besonderen Aufgabenstellungen, denen sie gerecht werden mußten, wurden mehr und mehr durch geeignete Abstraktionen in allgemein verwendbarer Form gelöst. Dementsprechend läßt sich das Modul RemoteNames heute direkt aus den entsprechenden Konventionen ableiten:
Bei der Implementierung der Aufträge muß darauf geachtet werden, wie die beteiligten Datenstrukturen im einzelnen zu transferieren sind. Die Abstraktion Names definiert einen zentralen Objekttyp (Names.Node) und verwendet eine Anzahl weiterer Typen für Prozedurparameter. In dieser Tabelle sind die bei der Übermittlung von Aufträgen zu benutzenden Schreiboperationen für jeden dieser Typen zusammengestellt, woraus sich auf naheliegende Weise auch die passenden Leseoperationen ableiten lassen. Parameter des Typs Names.Status stellen einen Sonderfall dar, weil sie (noch) nicht von allein persistent sind. Sie bestehen aber aus persistenten Komponenten und können daher mit einer aus einzelnen Schreiboperationen zusammengesetzten Operation weitergegeben werden.
Man beachte, daß sowohl Iteratoren als auch Ereignistypen importiert und exportiert werden können. Ebenfalls von Bedeutung ist, daß RemoteObjects den Mechanismus unterstützt, auf den die Standardimplementierung von Names angewiesen ist, um veraltete Namen entfernen zu können, nämlich die Abstraktion Resources, durch die unter anderem Nachrichten über die Termination von Objekten verbreitet werden. Als Konsequenz ergibt sich, daß Knoten, zu denen die Netzwerkverbindung endgültig abgebrochen ist, genau wie terminierte lokale Knoten mitsamt ihren Namen aus dem Namensraum verschwinden, und daß die Lebensdauer von Stellvertreter-Objekten die der Originalobjekte im Prinzip nicht überschreitet.
Da das Modul "im Verborgenen" (als Dienstanbieter) arbeitet, ist sein Definitionsteil leer.
![]()
Die Variable Names.root dient -- wie bereits erwähnt -- dazu, einzelnen Oberon-Programmen einen globaleren Namensraum als Kontext bereitzustellen. Unter anderem aus Gründen der Kontinuität werden Namensräume mit übergeordneter Bedeutung zumeist in eigens dazu bestimmten Dienstprogrammen, den Namensservern im engeren Sinn, etabliert werden. Andere Prozesse sollten in der Lage sein, mit einem für sie zuständigen und geeigneten Server Kontakt aufzunehmen, ohne auf festgelegte und daher unflexible Information zurückgreifen zu müssen.
Die Lösung, die für das Oberon-System unter UNIX gewählt wurde, sieht wie folgt aus: Aus einer Datei, deren Pfadname dem Laufzeitsystem bekannt ist, wird ein Oberon-Objekt des Typs Names.Node importiert. Es ist dies nicht etwa ein persistentes Objekt ungewisser Herkunft und Aktualität, sondern ein lebendes, von einem Namensserver exportiertes Objekt, falls überhaupt ein solcher existiert. Die von diesem Knoten ausgehenden Kanten sind dafür vorgesehen, in die Wurzel aller Oberon-Prozesse aufgenommen zu werden, die ihn erhalten haben. Eine solche Vorgehensweise wird dadurch möglich, daß der Export von Objekten kein synchroner bilateraler Vorgang ist, sondern durchaus auch zeitlich verzögerten Antworten mehrerer potentieller Adressaten gerecht werden kann. Erst beim Import wird ja die eigentliche Verbindung hergestellt.
Der Knoten aus dem lokalen bzw. netzgeographisch in der Nähe liegenden "Zwischenhändler" spielt keine Rolle mehr, nachdem er seine Aufgabe, eine Konfiguration von Knoten naher und ferner anderer Server weiterzugeben, erfüllt hat. Die seitens des Klienten erforderlichen Operationen, damit diese fremden Objekte über Namen in Names.root angesprochen werden können, führt das Modul UnixNames bei seiner Initialisierung aus.
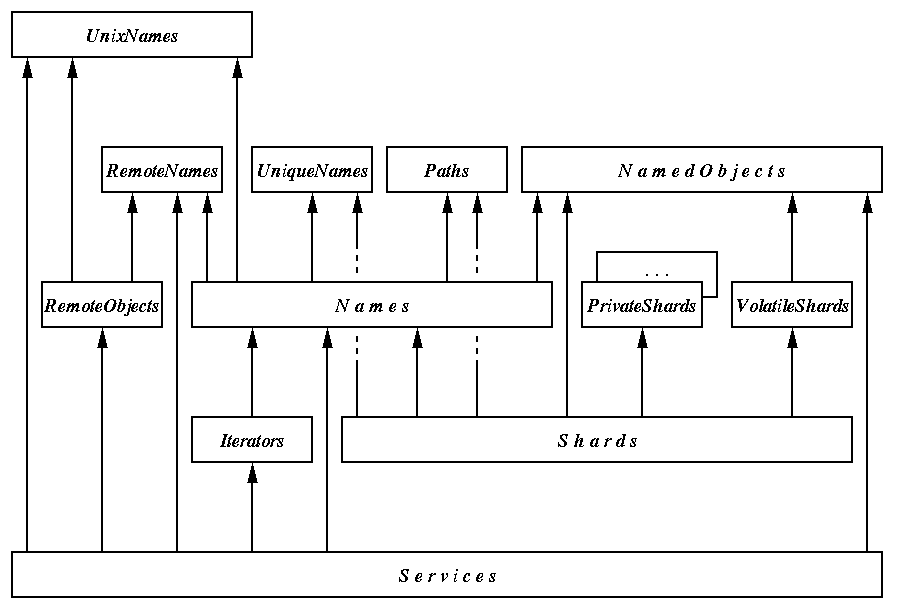 (Grafik, 10.5 KB)
(Grafik, 10.5 KB)
Modulhierarchie für Namensräume
Diese Abbildung, mit der dieses Kapitel endet, zeigt die Importhierarchie aller wichtigen mit Namensräumen zusammenhängenden Module.
![]()