![[Vorheriges Kapitel]](pprev.gif)
![[Vorherige Seite]](prev.gif)
![[Inhaltsverzeichnis]](up.gif)
![[Nächste Seite]](next.gif)
|
|
|
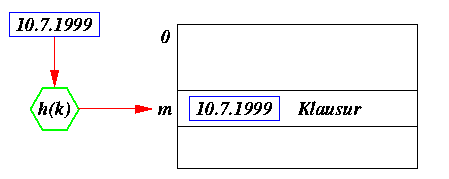
 | Hash-Verfahren versuchen, die Ermittlung eines
Datensatzes in Abhängigkeit eines Schlüssels k  K
mit Hilfe einer Hash-Funktion h: K -> M
zu vereinfachen, die einen Schlüssel k
in eine Speicherposition m M abbildet. K
mit Hilfe einer Hash-Funktion h: K -> M
zu vereinfachen, die einen Schlüssel k
in eine Speicherposition m M abbildet.
| ||||
| Leider ist es nicht trivial, selbst für eine auch nur
relativ kleine vorgegebene Menge von Schlüsseln K eine
Hash-Funktion zu finden, die injektiv ist, d.h.
| ||||
| Entsprechend sind Kollisionen auch bei geringen
Mengen an Schlüsseln sehr wahrscheinlich (Geburtstagsproblem).
| ||||
| Problemstellungen:
|
|
|
| Copyright © 1999 Andreas Borchert, in HTML konvertiert am 29.06.1999 |
 k1, k2
k1, k2  h(k2)
h(k2)