Content |
Intel 64 Architektur
Im Folgenden betrachten wir die Rechner Architektur x86-64 (auch Intel64 oder AMD64 genannt) genauer. Genauer gesagt wird hier ein Befehlssatz spezifiziert den ein Prozessor unterstützen muss. Implementiert wird diese Architektur zum Beispiel von den AMD Prozessoren Opteron, Athlon 64, Fusion, etc. und Intel Prozessoren Core 2, Core i5, i7, etc. Ein Maschinen Programm das diesen Befehlssatz benutzt kann also unmodifiziert auf jedem dieser Prozessor ausgeführt werden.
Register
Ein Prozessor Register ist ein Speicherplatz innerhalb der CPU. Soll die CPU zwei Zahlen (a und b), die im RAM liegen addieren (z.B. b = a + b), dann muss
-
der Wert von a und b zunächst jeweils in Register kopiert,
-
die Werte der Register addieren und
-
das Ergebnis wieder in b gespeichert werden.
Allgemein nutzbare Register
Die x86-64 Architectur bietet
-
16 allgemein nutzbare 64-Bit Register mit den sprechenden Namen %rax, %rbx, %rcx, %rdx, %rbp, %rsp, %rsi, %rdi, %r8, %r9, %r10, %r11, %r12, %r13, %r14, %r15. Wobei man aber nicht alle dieser Register beliebig nutzen kann!
-
8 x87 Register für 80 Bit Gleitkommazahlen (nicht direkt adressierbar).
-
16 SSE Register mit 128 Bit (%xmm0, ..., %xmm15):
-
Auf neueren Prozessoren: 16 256-Bit AVX Register (%ymm0, ..., %ymm15).
Ein 64-Bit Register kann auch als 32-Bit, 16-Bit Register benutzt werden. So kann man kann zum Beispiel die ersten 32 (bzw. 16) Bits direkt ansprechen. Teilweise kann man auch die ersten zwei Bytes (lower und higher 8-Bit) jeweils direkt ansprechen.
Im Assembler Code kann man dies über den Register Namen bzw. dem Anfangsbuchstaben steuern welcher Teil des Registers angesprochen wird. Zum Beispiel kann das %rax Register
-
mit %rax als 64-Bit Register angesprochen werden,
-
mit %eax als 32-Bit Register angesprochen werden,
-
mit %ax als 16-Bit Register angesprochen werden,
-
mit %al kann man die ersten 8-Bit und mit %ah die letzten 8-Bit von %ax angesprochen werden.
|
Name |
64-Bit |
Lower 32-Bit |
Lower 16-Bit |
Lower 8-Bits (erstes Byte) |
High 8-Bits (zweites Byte) |
|
Accumulator |
%rax |
%eax |
%ax |
%al |
%ah |
|
Base |
%rbx |
%ebx |
%bx |
%bl |
%bh |
|
Count |
%rcx |
%ecx |
%cx |
%cl |
%ch |
|
Data |
%rdx |
%edx |
%dx |
%dl |
%dh |
|
(Frame) base pointer |
%rbp |
%ebp |
%bp |
||
|
Stack pointer |
%rsp |
%esp |
%sp |
||
|
Source index |
%rsi |
%esi |
%si |
||
|
Destination index |
%rdi |
%edi |
%di |
||
|
Integer register |
%r8 - %r15 |
%r8d - %r15d |
%r8w - %r15w |
%r8b - %r15b |
Spezielle Register und Flags
Ein weiteres sehr spezielles Register ist %rip. Dabei steht ip für Instruction Pointer (synonym zu Program Counter (PC)). Dieses Register wird nie direkt verändert. Es wird aber von jeder Anweisung indirekt verändert! Der Wert in %rip ist die 64-Bit Speicher Adresse mit der als nächstes auszuführenden Anweisung. Wenn eine Anweisung ausgeführt wird, dann wird normalerweise der Wert von %rip so inkrementiert, dass %rip auf die folgende Anweisung verweist. Damit werden die Anweisungen also sequentiell abgearbeitet.
Gewisse “Jump” Anweisungen können %rip aber auch so ändern, dass Anweisung nicht in sequentieller Reihenfolge ausgeführt werden.
Weitere Register, die auch Flags genannt werden (da sie nur die Werte 0 oder 1 annehmen können) sind
|
Carry Flag |
CF |
|
Overflow Flag |
OF |
|
Sign Flag |
SF |
|
Zero Flag |
ZF |
|
Parity Flag |
PF |
|
Adjust Flag |
AF |
Die Flags werden ebenfalls implizit von gewissen Anweisungen geändert bzw. gesetzt. Von anderen Anweisungen kann deren Status wiederum abgefragt werden.
Speicher Layout
Den Speicher kann man Byte weise adressieren, d.h. jedes Byte hat eine eigene Adresse. Mit 64-Bit Registern kann man also \(2^{64} \text{Byte} = 2^{54} \text{KB} = 2^{44} \text{MB} = 2^{34} \text{GB} = 2^{24} \text{TB} = 2^{14} \text{PB} = 16 \text{EB}\)1 Speicherzellen adressieren.
Litte Endian / Big Endian
Mehrer Bytes werden zu größeren Datentypen zusammengefasst, z.B.
-
2 Bytes zu einem word,
-
4 Bytes zu einem double word (oder long)
-
8 Bytes zu einem quad word
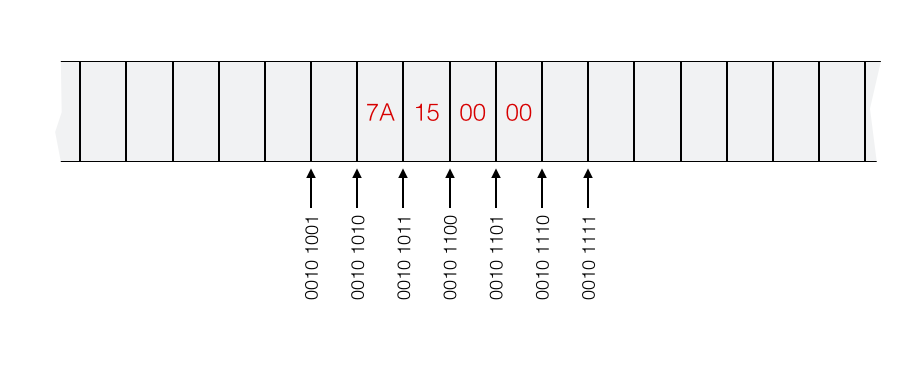
Sobald bei einem Datentyp mehr als ein Byte im Spiel ist muss man festlegen in welcher Reihenfolge die Bytes benutzt werden. Die Zahl \(5498 = (0000157A)_{16}\) = 0x0000157A sei an der Speicheradresse \((0010 1010)_2\) = 0010 1010b in einem quad word abgespeichert. Dann gibt es zwei Möglichkeiten:
-
Little Endian Konvention: Die einzelnen Bytes 00, 00, 15, 7A werden in umgekehrter Reihenfolge (least significant byte comes first) gespeichert:
-
Big Endian Konvention: Die einzelnen Bytes 00, 00, 15, 7A werden in dieser Reihenfolge (most significant byte comes first) gespeichert:
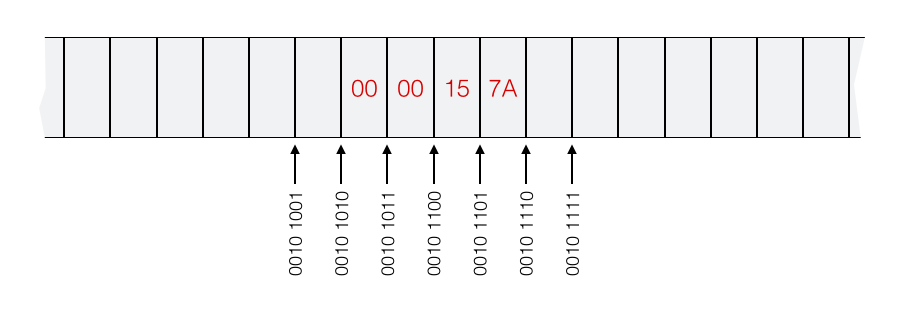
Auf der Intel Architektur wird aus historischen Gründen2 das little endian Format benutzt.
Laden eines Programms
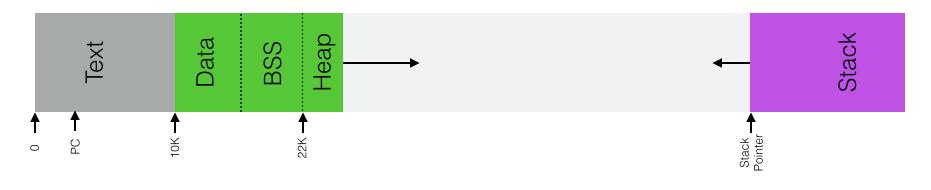
Ausführbare Programme werden in bestimmten Formaten abgespeichert3. Die Datei enthält den ausführbaren Maschinen Code und (nicht-trivial) initialisierte Daten (Konstanten und Variablen). Außerdem enthält das Programm die Information wie viele nicht initialisierte Variablen benötigt werden.
Wird das Programm gestartet, dann werden die Maschinen Befehle in das sogenannte Text-Segment und die initialisierten Daten ins Data-Segment geladen. Für nicht-initialisierte Daten wird der sogenannte BSS Bereich reserviert und mit Null initialisiert.
In das Stack-Segment wird der Name des Programms und übergebene Argumente kopiert. Das Stack Register wird auf den Anfang des Stapels gesetzt...
Schliesslich wird das %RIP Register (der Program Counter PC) Auf den ersten Maschinenbefehl gesetzt.
Aufgaben
Disassembler
Es gibt die Möglichkeit aus einer Ausführbaren Datei wieder den Assembler Code zu rekonstruieren. Unter Mac OS X gibt es dafür zum Beispiel das Programm otool. Wir wollen dieses Tool benutzen um zu prüfen, ob das oben gesagt auch stimmt.
Folgendes Programm benutzen wir zum Demonstration (abtippen oder abspeichern):
unsigned b = 2;
int c;
int
main()
{
c = 3;
return a + b +c;
}
Wir übersetzen und Linken (nachmachen):
$shell> gcc-4.8 -Wall simple.c
Jetzt rufen wir den Disassembler auf (nachmachen und mittels RTFM herausfinden was die Optionen tun sollen):
$shell> otool -tdV a.out
a.out:
(__TEXT,__text) section
_main:
0000000100000f82 pushq %rbp
0000000100000f83 movq %rsp, %rbp
0000000100000f86 leaq _c(%rip), %rax
0000000100000f8d movl $0x3, (%rax)
0000000100000f93 movl _a(%rip), %eax
0000000100000f99 movl %eax, %edx
0000000100000f9b movl _b(%rip), %eax
0000000100000fa1 addl %eax, %edx
0000000100000fa3 leaq _c(%rip), %rax
0000000100000faa movl (%rax), %eax
0000000100000fac addl %edx, %eax
0000000100000fae popq %rbp
0000000100000faf ret
(__DATA,__data) section
0000000100001000 01 00 00 00 02 00 00 00
RTFM: Was stellt die Ausgabe dar??
Man sieht, dass in der Ausführbaren Datei sogar noch Informationen aus dem Source File enthalten sind. Denn es tauchen die Namen der Variablen auf. Ok, bis auf den häßlichen Unterstrich (Die Namen der Variablen ändern und das Ganze Wiederholen).
Diese Meta-Informationen kann man aus der Ausführbaren Datei löschen. Symbole die dort der Lesbarkeit wegen benutzt wurden werden dann mit nackten Zahlen ersetzt. Dazu benutzt man das Tool strip (RTFM) und schaut sich nochmals das Ergebnis von otool an.
$shell> strip a.out $shell> otool -tdV a.out a.out: (__TEXT,__text) section 0000000100000f82 pushq %rbp 0000000100000f83 movq %rsp, %rbp 0000000100000f86 leaq 0x7b(%rip), %rax 0000000100000f8d movl $0x3, (%rax) 0000000100000f93 movl 0x67(%rip), %eax 0000000100000f99 movl %eax, %edx 0000000100000f9b movl 0x63(%rip), %eax 0000000100000fa1 addl %eax, %edx 0000000100000fa3 leaq 0x5e(%rip), %rax 0000000100000faa movl (%rax), %eax 0000000100000fac addl %edx, %eax 0000000100000fae popq %rbp 0000000100000faf ret (__DATA,__data) section 0000000100001000 01 00 00 00 02 00 00 00
Aufschreiben:
-
Mit welchen Zahlen wurde _a, _b, _c ersetzt?
-
Es taucht mehrfach das Register %rip auf. Welchen Wert sollte %rip jeweils haben.
(Nachtrag) Global Offset Table
Oben wurde aus dem Source File simple.c direkt eine ausführbare Datei erzeugt, das heisst es wurde übersetzt und gelinkt. Wenn wir den Assembler Code vor dem Linken anschauen sehen wir ein neues Schlüsselwort GOTPCREL:
$shell> gcc-4.8 -Wall -S -fno-asynchronous-unwind-tables simple.c $shell> cat simple.s .globl _a .data .align 2 _a: .long 1 .globl _b .align 2 _b: .long 2 .comm _c,4,2 .text .globl _main _main: pushq %rbp movq %rsp, %rbp movq _c@GOTPCREL(%rip), %rax movl $3, (%rax) movl _a(%rip), %eax movl %eax, %edx movl _b(%rip), %eax addl %eax, %edx movq _c@GOTPCREL(%rip), %rax movl (%rax), %eax addl %edx, %eax popq %rbp ret .subsections_via_symbols
Dabei steht GOT für Global Offset Table, PC für Programm Counter (das ist synonym zu Instruction Pointer) und REL für Relative. Mit _c@GOTPCREL(%rip) ist also die Adresse von _c relativ zum Wert von %rip gemeint.
Uninitialisierte Daten werden wie oben erwähnt im BSS Segment angelegt. Wo das Data und BSS Segment in der ausführbaren Datei letztlich beginnt weiss man erst nach dem Linken. Für initialisierte Daten hat man aber in jedem Object File schon einmal ein Label. Damit ist klar was mit _a(%rip) gemeint ist. Da c aber nicht initialisiert ist wird für _c kein Label angelegt (Der Speicher für c wird ja erst vom Programm Lader angelegt und mit Null Initialisiert). Der Linker sammelt aber aus jedem Object File die Information welche Daten später für das BSS Segment benötigt werden. Diese werden in der GOT verwaltet.
Fussnoten
- 1Ja, ich weiss. Heutzutage muss man KiB, MiB, usw. sagen. Denn der Kunde ist König und hat keine Ahnung vom Binärsystem. Also muss ein Mega Byte eine Million Byte sein. Aber wie sieht es aus mit Mega Perls? Ich habe nachgezählt!
- 2Es gab vor langer Zeit tatsächlich mal praktische Gründe für dieses Format!
- 3Zum Beispiel Mach-O bei Mac OS X, ELF unter Linux oder a.out in historischen Unix Versionen.