Spätestens mit der Publizierung von Dijkstra über ``The Structure of `THE'-Multiprogramming System'' im Jahre 1968 wurde eine Strukturierung eines Systems in Schichten entsprechend der Abhängigkeiten populär (siehe Abbildung 3.1). Er zerlegte sein Betriebssystem in fünf Schichten, bei der jede Ebene auf dem Weg von unten nach oben bestimmte Hardware-Ressourcen in abstrakter und virtueller Form zur Verfügung stellte. Bei dieser Strukturierung war sichergestellt, daß jede Ebene nur Aufrufe an sich selbst und die untergeordneten Ebenen absetzt. Damit eröffnet sich nicht nur eine leichtere Verstehbarkeit eines solchen Systems - die einzelnen Ebenen lassen sich auch leichter testen oder austauschen.
Die gleiche Motivation führte auch zu den Schichten aus dem ISO-Referenz-Modell für Netzwerk-Software (siehe Abbildung 3.2).
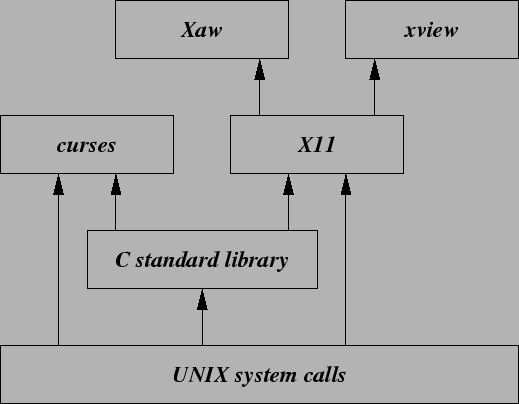
Genauso wie bei dem THE-System von Dijkstra sind mit den einzelnen Schichten Schnittstellen verbunden, und jede Schicht implementiert ein Protokoll mit seiner eigenen Ebene auf der Seite des Kommunikationspartners, das den anderen Schichten verborgen bleibt. Auf diese Weise ähneln Kommunikationspakete russischen Puppen, bei denen jede Schicht nach und nach ihre privaten Informationen generiert (bzw. auf der anderen Seite liest), um dann das Paket der übergeordneten Ebene einzubauen (bzw. herauszunehmen und weiterzugeben).Genauso wie bei Software-Systemen liegt es auch nahe, bei Bibliotheken Schichten einzuführen. Die Abbildung 3.3 zeigt einen Ausschnitt der Schichten der Bibliotheken in C.
Typisch für die Bibliotheksstruktur klassischer Programmiersprachen ist der Aufbau, der mit systemnahen Modulen unten beginnt und nach oben mit eher system-unabhängigen Schichten fortgesetzt wird. Zwar läßt sich beispielsweise eine der Schichten ersetzen, dennoch sind die Abhängigkeiten zu UNIX von curses und X11 unübersehbar. Selbst bei der Beschränkung auf obere Schichten ohne direkten Import der Systemschnittstelle besteht immer das Risiko, daß Systemabhängigkeiten indirekt eingeführt werden. So verwendet und exportiert beispielsweise die C-Standard-Bibliothek eine Reihe von Datentypen, die in der Ebene der Systemaufrufe definiert werden.Durch die Verwendung objekt-orientierter Techniken lassen sich jedoch die Schnittstellendefinitionen von den zugehörigen Implementierungen trennen, und damit ist es möglich, dieses Beziehungsgeflecht vollkommen umzustülpen.
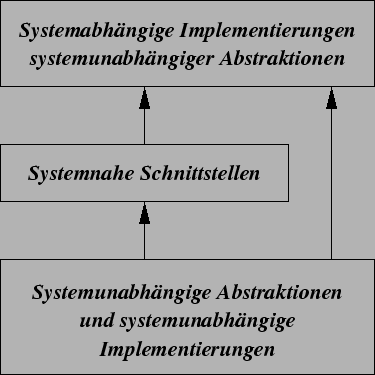
Wie Abbildung 3.4 zeigt, ist es nun möglich, alle Abstraktionen mitsamt den systemunabhängigen Implementierungen in die unterste Schicht zu verlagern. Es läßt sich sogar erreichen, daß eine Applikation nur aus dieser Schicht importiert und damit eine garantierte Systemunabhängigkeit besitzt. Weiter darüber folgt eine systemabhängige Ebene, die eine möglichst sprachnahe Schnittstelle zum System offeriert. Dabei können verschiedene Module aus der systemunabhängigen Schicht importiert werden wie z.B. Mechanismen zur Ausnahmenbehandlung. In der obersten Ebene werden dann Implementierungen der systemunabhängigen Abstraktionen hinzugefügt, die von der Systemschnittstelle aus der mittleren Ebene abhängen.Natürlich beschränkt sich eine objekt-orientierte Bibliothek sich nicht in jedem Fall auf drei Schichten. Sehr häufig entstehen Schichten, indem bestimmte Funktionalitäten zu Paketen geschnürt werden (z.B. eine Schicht für Container, eine für Persistenz und die nächste für verteilte Systeme). Oder es existieren mannigfaltige externe Abhängigkeiten (z.B. zu einem bestimmten Betriebssystem, einer bestimmten Netzwerkarchitektur, einer Datenbank usw.), die dann entsprechende Schichtenpaare hinterlassen (je eine als direkte Schnittstelle und eine mit darauf basierenden Implementierungen, wobei dies manchmal auch gleich zusammengefaßt wird).
Darüber hinaus ist es denkbar, verschiedene Schicht-Systeme parallel zu unterhalten, die die gleiche Menge an Modulen unterschiedlich unterteilen, z.B. auf der einen Seite funktional orientiert und auf der anderen Seite nach Abhängigkeiten sortiert. Allerdings wird dies normalerweise nicht praktiziert und allenfalls im Rahmen der Dokumentation virtuell erzeugt.
Die Strukturierung in Schichten wird üblicherweise nicht direkt von den objekt-orientierten Programmiersprachen unterstützt. Allerdings gibt es bei einzelnen Programmiersprachen (insbesondere Eiffel (cluster) und BETA (fragments)) vorgegebene Meta-Sprachen, während bei anderen Programmiersprachen auf die Dienste des Betriebssystems oder anderer spezieller Pakete zurückgegriffen wird. Im einfachsten Fall werden einzelne Schichten in entsprechenden Verzeichnissen untergebracht - so auch bei Oberon.
Die Ulmer Oberon-Bibliothek ist in folgenden acht Schichten organisiert: