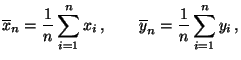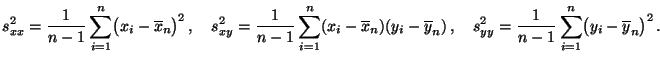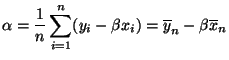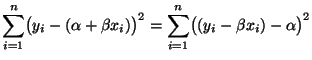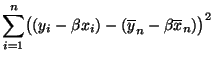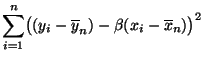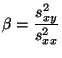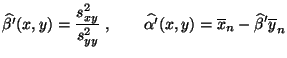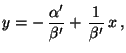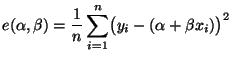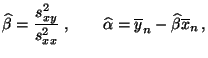Wir diskutieren zunächst die folgende Methode der kleinsten
Quadrate (MKQ) zur Bestimmung von Schätzwerten
,
für die unbekannten Parameter
, bei der keine zusätzlichen Voraussetzungen über
die Störgrößen
benötigt werden.
Und zwar sollen
,
so bestimmt
werden, daß der mittlere quadratische Fehler
(3)
für
minimal wird,
wobei wir voraussetzen, daß und daß nicht alle
gleich sind.
minimiert den mittleren quadratischen Fehler
,
wobei
,
die Stichprobenmittel
bezeichnen, d.h.
und die Stichprobenvarianzen
bzw. die
Stichprobenkovarianz gegeben sind durch
Beweis
Die Minimierung kann wie folgt durchgeführt werden: Durch
Differenzieren nach erkennt man, daß für jedes fest
vorgegebene
die Zahl
den Wert des Ausdruckes
minimiert.
Mit anderen Worten: Für jedes fest vorgegebene
ist
der kleinste Wert des mittleren quadratischen Fehlers.
Durch Differenzieren dieses Ausdruckes nach ergibt sich
nun, daß das globale Minimum an der Stelle
angenommen wird.
Beachte
Der in (3) definierte mittlere quadratische Fehler
ist der mittlere quadratische vertikale
Abstand zwischen den Punkten und den Werten
der Regressionsgeraden
an den Stellen
.
Anstelle der vertikalen Abstände kann man beispielsweise auch die
horizontalen Abstände betrachten. Durch Vertauschen der Rollen von
und ergibt sich dann der MKQ-Ansatz
zur Schätzung der Parameter
der
(inversen) Regressionsgeraden
.
Wenn wir diese Geradengleichung nach auflösen, dann ergibt
sich die Gleichung
wobei allerdings die Schätzer
und
für Regressionskonstante bzw.
Regressionskoeffizient im allgemeinen verschieden von den
Schätzern
bzw.
sind, die in
(4) hergeleitetet worden sind.
Beispiel
(vgl. Casella/Berger (2002) Statistical
Inference, Duxbury, S. 540ff.)
Im Weinanbau werden die jeweils im Herbst geernteten Erträge in
Tonnen je 100 m (t/ar) gemessen.
Es ist bekannt, daß der Jahresertrag bereits im Juli ziemlich gut
prognostiziert werden kann, und zwar durch die Bestimmung der
mittleren Anzahl von Beeren, die je Traube gebildet worden sind.
Mit Hilfe des folgenden Zahlenbeispiels soll illustriert werden,
wie die einfache lineare Regression zur Vorhersage des
Jahresertrages dienen kann.
Dabei fassen wir den Jahresertrag als Zielvariable () auf,
und die mittlere Clusterzahl je Traube () als
Ausgangsvariable.
Jahr
Ertrag ()
Clusterzahl ()
1971
5.6
116.37
1973
3.2
82.77
1974
4.5
110.68
1975
4.2
97.50
1976
5.2
115.88
1977
2.7
80.19
1978
4.8
125.24
1979
4.9
116.15
1980
4.7
117.36
1981
4.1
93.31
1982
4.4
107.46
1983
5.4
122.30
Die Daten des Jahres 1972 fehlen, weil in diesem Jahr das
untersuchte Weinanbaugebiet von einem Wirbelsturm verwüstet worden
war.
Übungsaufgabe
(vgl. auch Übungsaufgabe 1.1)
Zeichnen Sie ein Streuungsdiagramm (Punktwolke) für die
beobachteten Daten.
Bestimmen Sie für dieses Zahlenbeispiel die Schätzer
und
sowie
und
und
zeichnen Sie die geschätzte Regressionsgerade in das
Streuungsdiagramm ein.
Prognostizieren Sie mit Hilfe der geschätzten Regressionsgerade
den Jahresertrag, der
einer mittleren Clusterzahl von 100 Beeren je Traube entsprechen
würde.