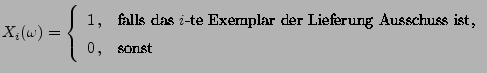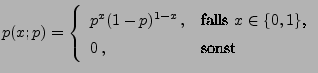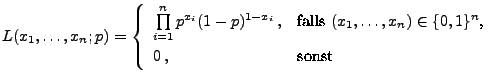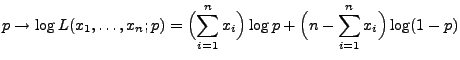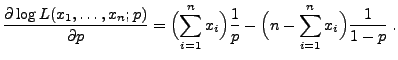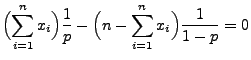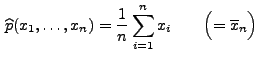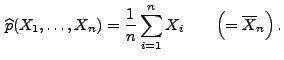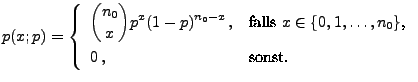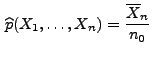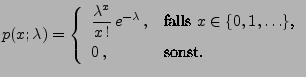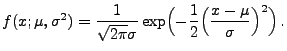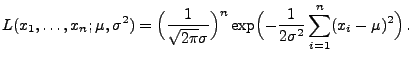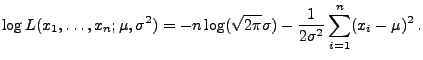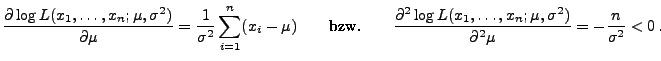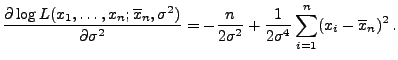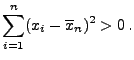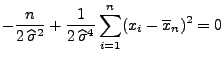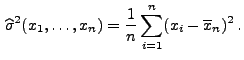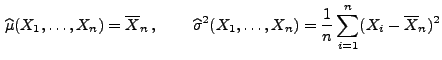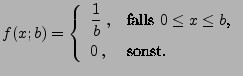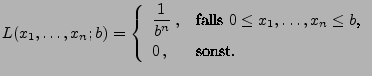Nächste Seite: Bayes-Schätzer
Aufwärts: Methoden zur Gewinnung von
Vorherige Seite: Momenten-Methode
Inhalt
Maximum-Likelihood-Schätzer
- Eine andere Methode zur Gewinnung von Schätzern für die
unbekannten Komponenten des Parametervektors
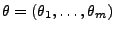 ist die
Maximum-Likelihood-Methode.
ist die
Maximum-Likelihood-Methode.
- Genauso wie bei der Momentenmethode wird auch bei der
Maximum-Likelihood-Methode das Ziel verfolgt,
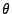 so zu
schätzen, dass eine möglichst gute Anpassung der Modellverteilung
so zu
schätzen, dass eine möglichst gute Anpassung der Modellverteilung
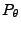 bzw. der Verteilungsfunktion
bzw. der Verteilungsfunktion 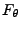 an die
beobachteten Daten
an die
beobachteten Daten
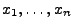 erreicht wird.
erreicht wird.
Wir betrachten hier nur die beiden (grundlegenden) Fälle, dass die
Stichprobenvariablen
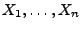 entweder diskret oder
absolutstetig sind. D.h., für jedes
entweder diskret oder
absolutstetig sind. D.h., für jedes
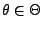 gelte
entweder
gelte
entweder
-
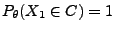 für eine abzählbare Menge
für eine abzählbare Menge
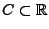 ,
wobei wir mit
,
wobei wir mit
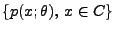 die
Wahrscheinlichkeitsfunktion von
die
Wahrscheinlichkeitsfunktion von 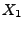 bezeichnen, d.h.
bezeichnen, d.h.
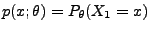 für jedes
für jedes
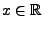 , oder
, oder
-
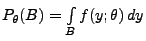 für jedes
für jedes
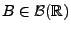 , wobei
, wobei
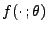 die Dichte von
ist.
die Dichte von
ist.
Dabei wird bei der Maximum-Likelihood-Methode der Parametervektor
so gewählt, dass
- im diskreten Fall die Wahrscheinlichkeit
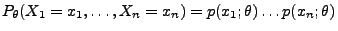 des Ereignisses
des Ereignisses
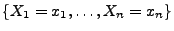 bzw.
bzw.
- im absolutstetigen Fall die ,,infinitesimale'' Wahrscheinlichkeit
maximiert wird.
Die Maximum-Likelihood-Methode wurde bereits im Jahre 1821 von
Carl Friedrich Gauss (1777-1855) erwähnt. Sir Ronald Aylmer
Fisher (1890-1962) hat diese Methode dann im Jahre 1922
wiederentdeckt und mit der Untersuchung ihrer Eigenschaften
begonnen.
- Definition
 Die Abbildung
Die Abbildung
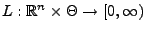 sei durch die folgende
Vorschrift gegeben.
sei durch die folgende
Vorschrift gegeben.
- Falls diskret ist, dann sei
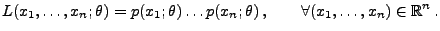 |
(12) |
- Falls absolutstetig ist, dann sei
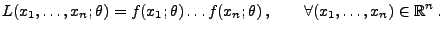 |
(13) |
Für jeden Vektor
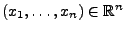 heißt die Abbildung
heißt die Abbildung
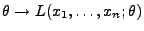 , die den Parameterraum
, die den Parameterraum
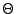 nach
nach
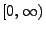 abbildet, die Likelihood-Funktion
der Stichprobe
abbildet, die Likelihood-Funktion
der Stichprobe
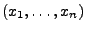 .
.
Die Idee der Maximum-Likelihood-Methode besteht nun darin, für
jede (konkrete) Stichprobe
einen
Parametervektor
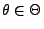 zu bestimmen, so dass der Wert
zu bestimmen, so dass der Wert
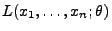 der Likelihood-Funktion möglichst groß
wird. Dies führt zu der folgenden Begriffsbildung.
der Likelihood-Funktion möglichst groß
wird. Dies führt zu der folgenden Begriffsbildung.
- Definition
- Sei
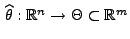 eine
Stichprobenfunktion mit
eine
Stichprobenfunktion mit
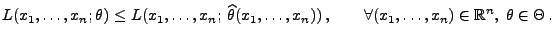 |
(14) |
Der Zufallsvektor
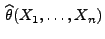 wird dann
Maximum-Likelihood-Schätzer für (bzw. kurz:
ML-Schätzer) genannt.
wird dann
Maximum-Likelihood-Schätzer für (bzw. kurz:
ML-Schätzer) genannt.
- Beachte
-
- Beispiele
-
- Wer war vermutlich der Absender?
- Bernoulli-verteilte Stichprobenvariablen (Fortsetzung)
- Betrachten die Familie
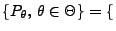 Bin
Bin
![$ (1,p),\,p\in[0,1]\}$](img738.png) der Bernoulli-Verteilungen.
der Bernoulli-Verteilungen.
- Dann gilt
- Die Likelihood-Funktion
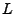 ist also gegeben durch
ist also gegeben durch
- Falls
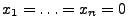 bzw.
bzw.
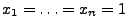 , dann
sieht man leicht, dass
die Abbildung
, dann
sieht man leicht, dass
die Abbildung
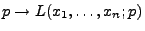 an der Stelle
an der Stelle 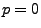 bzw.
bzw. 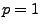 ein
(eindeutig bestimmtes) Maximum hat.
ein
(eindeutig bestimmtes) Maximum hat.
- Sei nun
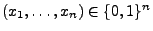 mit
mit
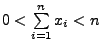 . Dann ist
eine stetige Funktion im Intervall
. Dann ist
eine stetige Funktion im Intervall 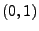 , und es gilt
, und es gilt
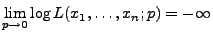
bzw.
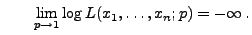
- Die Abbildung
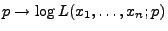 hat also ein Maximum im
Intervall .
hat also ein Maximum im
Intervall .
- Durch Differenzieren nach
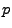 ergibt sich
ergibt sich
- Weil die Gleichung
die (eindeutig bestimmte) Lösung
hat, nimmt die Abbildung
an der Stelle
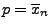 ihr Maximum an.
ihr Maximum an.
- Also ist der Maximum-Likelihood-Schätzer für den Parameter
gegeben durch
- Ein JAVA-Applet zur Visualisierung der Loglikelihood-Funktion
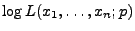 findet man
beispielsweise auf der Internet-Seite:
findet man
beispielsweise auf der Internet-Seite:
- http://www.math.gatech.edu/~spruill/applets.html
- Binomialverteilte Stichprobenvariablen
- Für eine beliebige, jedoch vorgegebene
(d.h. bekannte) natürliche Zahl
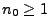 betrachten wir nun
die Familie
betrachten wir nun
die Familie
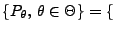 Bin
Bin
![$ (n_0,p),\,p\in[0,1]\}$](img761.png) von Binomialerteilungen.
von Binomialerteilungen.
- Dann gilt
- Genauso wie in Beispiel 2 ergibt sich der
Maximum-Likelihood-Schätzer
für den (unbekannten) Parameter .
- Poisson-verteilte Stichprobenvariablen
- Betrachten die Familie
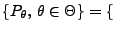 Poi
Poi
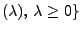 der Poisson-Verteilungen.
der Poisson-Verteilungen.
- Dann gilt
- Auf die gleiche Weise wie in den Beispielen 2 und 3 ergibt sich der
Maximum-Likelihood-Schätzer
für den Parameter
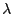 .
.
- Normalverteilte Stichprobenvariablen
- Betrachten nun die Familie
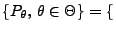 N
N
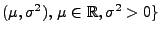 der Normalverteilungen.
der Normalverteilungen.
- Dann gilt
- Die Likelihood-Funktion ist somit gegeben durch
- Für die Loglikelihood-Funktion gilt
- Durch Differenzieren nach
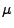 ergibt sich
ergibt sich
- Für jedes (fest vorgegebene)
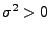 nimmt also die
Abbildung
ihr Maximum an der Stelle
nimmt also die
Abbildung
ihr Maximum an der Stelle
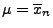 an.
an.
- Es ist nun noch das Maximum der Abbildung
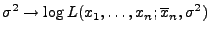 |
(16) |
zu bestimmen.
- Weil
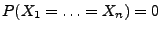 gilt, können wir annehmen, dass
nicht alle Stichprobenwerte
gleich sind.
gilt, können wir annehmen, dass
nicht alle Stichprobenwerte
gleich sind.
- Beachte: Die Abbildung (16) ist stetig für alle
,
und es gilt
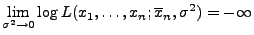
bzw.
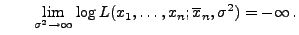
- Die Abbildung (16) hat also ein Maximum im
Intervall
 .
.
- Durch Differenzieren nach
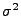 ergibt sich
ergibt sich
- Weil vorausgesetzt wird, dass nicht alle Stichprobenwerte
gleich sind, gilt
- Deshalb hat die Gleichung
die (eindeutig bestimmte) Lösung
- Hieraus ergeben sich die Maximum-Likelihood-Schätzer
für die Parameter und .
- Ein JAVA-Applet zur Visualisierung der Loglikelihood-Funktion
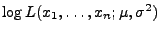 und verschiedene
(numerische) Algorithmen zur Berechnung von
und verschiedene
(numerische) Algorithmen zur Berechnung von
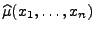 bzw.
bzw.
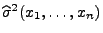 findet man
beispielsweise auf der Internet-Seite:
findet man
beispielsweise auf der Internet-Seite:
- http://stat.tamu.edu/~jhardin/applets/signed/optim.html
- Gleichverteilte Stichprobenvariablen
- Betrachten die Familie
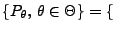 U
U
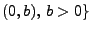 von Gleichverteilungen.
von Gleichverteilungen.
- Dann gilt
- Die Likelihood-Funktion ist somit gegeben durch
- Weil die Abbildung
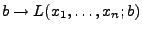 monoton
fallend ist für
monoton
fallend ist für
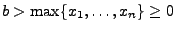 , ergibt
sich der Maximum-Likelihood-Schätzer
, ergibt
sich der Maximum-Likelihood-Schätzer
für den Parameter 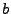 .
.
Nächste Seite: Bayes-Schätzer
Aufwärts: Methoden zur Gewinnung von
Vorherige Seite: Momenten-Methode
Inhalt
Ursa Pantle
2004-07-14